|
|
High Energy Physics Libraries Webzine |
|
|
|
|
|
HEP
Libraries Webzine
SetLink: the CERN Document Server Link ManagerCERN-ETT-2000-001
This paper will stress the importance of
using a Link Manager for any long term Web server. It will explain how
the CERN SetLink Link Manager is designed to handle a wide range of document
types and formats, from photos in JPEG to eprints in PDF. It will also
focus on other possibilities offered by using such an application, like
automatic figures extraction or concatenation, full text searching and
on-the-fly format conversions.
Background: the CERN library and Document ServerIn order to scale the problem, this first part shortly describes an example of an average size library with a huge amount of electronic resources: the CERN library. As of 15th February 2000 this database contains more than 380.000 documents in the form of bibliographic notices and more than 140.000 documents are available in an electronic format for full text download.A large repository of meta-data ... and of dataCERN is the European Organization for Nuclear Research [1], situated in Switzerland, near to Geneva. It is CERN policy to publish many of its findings so the library keeps huge numbers of preprints, books, periodicals, conference reports and High Energy Physics institute papers amongst other things.This vast repository of meta-data contains more than 255 000 preprints, 43 000 books, 1 200 periodicals, 9 000 administrative documents, 25 000 official archived records, 2 050 photos, 1500 press cuttings, etc., and it is always growing. The description of a document (its fields) is achieved using a customization of the very complete MARC [2] format, stored in the Aleph automated library system [3]. The CERN system is also composed
of a large quantity of data: electronic versions of full text documents
(PS and PDF), paper versions which are scanned to be delivered electronically,
eprints, scientific committee papers, academic training, photos, press
cuttings, etc. The CERN Document Server stores today about 70 000 files,
which represents about half of the total fulltext linking done from the
Library system.
Two types of URLAll of the library is available through the Web, using WebLib [4] which is a search engine built on top of the meta-data. In order to enable users to access full text of documents (if available), a URL must be provided so that the search finally leads to its final objective: read the document !As any Internet user will confirm, the trouble with URL is its very short lifetime. The so-called "U-N-F" - URL Not Found - problem can result from changes at three levels: the protocol (ftp -> http -> https) which is rare, the server name (Error 602: Connection failed) which is more often and the file names (the famous Error 404) which is so frequent. In order to cope with this problem within the library system, we distinguish two types of URL, the stored ones and the derived ones.
They are considered as controlled URL if they point to the CERN document server or to some official CERN site (which will be maintained for the lifetime of CERN). They are uncontrolled URL if they link to documents or pages outside the laboratory, or possibly to "wild" CERN servers. Of course, this last type of URL are the most problematic. In order to isolate broken links, the only solution is to run an URL Checker like MOMspider [5] which is run regularly until it can certify the address is broken. Correction or deletion must then be done "manually", one by one. The first time it was run on the book collection (summer 1998), already half of the URL were obsolete. In general, the stored URL are easy to collect and to check but their maintenance is a real pain, even with the help of software. It can be derived from a report number, from a publication reference, from a conference code or from any other key value. The link is generated by the program displaying the results of a search. The main trouble encountered with this type of URL is that broken addresses are generally discovered by chance. No URL checkers can be run on "on-the-fly" URL. If an electronic journal changes the organization of its articles URL, or if it disappear, all the links to it become dead links. The advantage of this technology is that a single maintenance action (e.g.: remove the e-journal name in the list of CERN e-jounals on-line) will be understood by the program, and all the linking remains valid. Sometimes, it may be more complex (e.g.: introducing issue numbers in URL to articles) and it then requires some maintenance at the programming level. Still, only one maintenance effort may correct thousands of links. So, even if it is a bit problematic to check the persistency of derived URL, they are much easier to maintain than uncontrolled stored URL. General solutions to broken linksWe are not going into the details of the various solutions proposed to solve the global Addressing Internet problem [6]. Let us only mention the long-term solution of URN, Uniform Resource Name, which is a generic name for many possible physical names. The basic idea is that Domain name servers will be able to handle URNs in order to find out correct URL (locators).Meanwhile, resolution services should exist on the Web servers themselves. Links to files should be systematically replaced by links to a resolution application (a link manager) in charge of fetching the requested page. Examples of such a technology are PURL (Persistent URL system) [7] or DOI (Digital Object Identifier) [8]. As the CERN library system is not only a "URL consumer" but also a "URL provider" - many sites are pointing to library resources or to full text documents - The CERN Document Server has developed its own link manager (called SetLink) which serves today the 70 000 full text documents and photos. In this way, all links from the library databases to the CERN Document Server will be long term: independent from server names, files locations or files formats. We will see in the next chapter what is
the SetLink link manager and why it was decided to use an in-house link
manager instead of a commercial alternative.
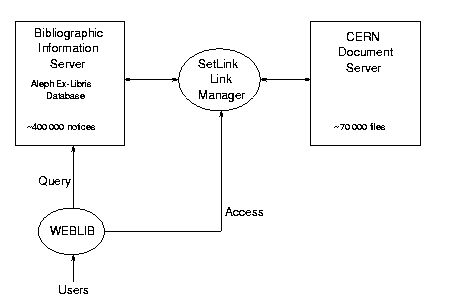
The SetLink Link ManagerEach record in the library databases, whether its a photograph, a preprint, or whatever, can be found using three simple string parameters: base, category and ID. The base defines the type of document you are looking for, "preprint" for preprints, "PHO" for photographs, etc. Category divides the base into sections, maybe by class or by year, and ID provides a simple identifier for each record within the class, often this is simply an 8 digit number, but it can be a more complex string. SetLink uses this same system to retrieve the files over the web in order to provide consistency and stability in-between the ALEPH database and the CERN Document Server.SetLink is not a search engine, but for a given base, category and ID combination it should be able to return the document the user is searching for, and offer some additional services in return. You can, for example, convert the document files to other file formats such as PDF, PostScript or even into a GIF image page by page, perform keyword searches on PDF documents, or send the document to a local printer or to your email account, all from the same web page returned by SetLink. Overview of the structure of WebLib, SetLink and CDS: |
In order that the HTML be interactive with the program a few rudimentary codes were inserted into the HTML, now known as dollar commands because they are preceded with a "$" character. At first these were reasonably simple things such as $Fn for a filename. Hyperlinks to a document file are created thus;
Very different examples of what SetLink can render can be seen at the URLs below:But whatever is the evolution of the technologies, the current use of the SetLink link manager is a guarantee of a minimal impact on the maintenance of the CERN library system and at the same time the assurance of the ability to quickly link all bibliographic notices to the best corresponding resources.
Finally, we are optimistic that more and
more URL providers (like e-journals already involved in Cross References
service [12]) will be using link
managers in order to decrease the "Error 404" rate and to improve the quality
of library services world-wide.
|
|
|
|