 High Energy Physics Libraries
Webzine
High Energy Physics Libraries
Webzine| High Energy Physics Libraries
Webzine |
|
HEP Libraries Webzine
Issue 12 / March 2006
11/01/2006
At the end of 2004, Google launched the beta version of a new service, Google Scholar, which provides a single repository of scholarly information for researchers. Will this service replace metasearch systems?
Metasearch systems are based on just-in-time processing, whereas Google Scholar, like other federated searching systems, is based on just-in-case processing. This underlying technology, along with Google Scholar's exceptional capabilities, accords Google Scholar a unique position among other scholarly resources. However, a year after its beta release, Google Scholar is still facing a number of challenges that cause librarians to question its value for scholarly research. Nevertheless, it has become popular among researchers, and the library community is looking for ways to provide patrons with guidelines for the most beneficial manner of using this new resource.
Metasearch systems have several advantages over Google Scholar. We anticipate that in the foreseeable future, libraries will continue to provide access to their electronic collections via their branded, controlled metasearch system.
Metasearch, federated search, CrossRef CrossSearch, relevance ranking, Google Scholar, search engine,
clustering search engine
Google as a Web search engine has undoubtedly had a great impact on all those who search for information on the Web. The instant response, huge repositories, sophisticated search mechanism and relevance-ranking feature have combined to make Google the most popular Web search engine.
In late 2004, Google launched several exciting products, one of which is a beta version of Google Scholar. Aiming to provide a single repository for scholarly information, Google Scholar enables users to search for peer-reviewed papers, theses, books, preprints, abstracts, and technical reports in many academic areas. Furthermore, according to information released by Google, Google Scholar arranges results by relevance, taking into account the number of times that the item has been cited in scholarly literature, as well as other criteria [1]. Equipped with this unique ranking process, unparalleled hardware resources, sophisticated crawling techniques, and access to published materials, Google is positioning Google Scholar to be an essential resource for the scholarly environment. In the not too distant future, Google is likely to be facing rivals such as MSN and Yahoo!, who may offer similar products.
Still at the beta stage a year after its initial launch, Google Scholar has stimulated lively debate in the library community. Of particular interest to many is the question of whether Google Scholar is a potential competitor of metasearch systems and, if so, whether it will replace them or coexist with them as yet another channel to scholarly information.
Before evaluating Google Scholar and its impact on the scholarly environment, let us examine the historical roots of the methodologies underlying systems such as Google Scholar.
We will start by clarifying the terms 'metasearch system' and 'federated search system' as used in this paper. These terms are frequently interchanged, but for our purposes, we would like to draw a distinction.
Metasearching, also known as integrated searching, simultaneous searching, cross-database searching, parallel searching, and broadcast searching, is a process in which a user submits a query to numerous information resources simultaneously. The resources can be heterogeneous in many respects: their location, the format of the information that they offer, the technologies on which they draw, the types of materials that they contain, and more. The user's query is broadcast to each resource, and results are returned to the user.
The development of software products that offer metasearching relies on the fact that each information resource has its own search engine. The metasearch system transmits a user's query to that search engine and directs it to perform the actual search. Upon receiving the results of the search, the metasearch system displays them to the user (Fig. 1). This process involves, first, the adaptation of the query's format to the specific requirements of the search engine at the target's end, and next, the conversion of the results to a unified format. The unified format later enables the metasearch system to process the results further - including displaying them in a consistent manner, merging them, and de-duplicating them.
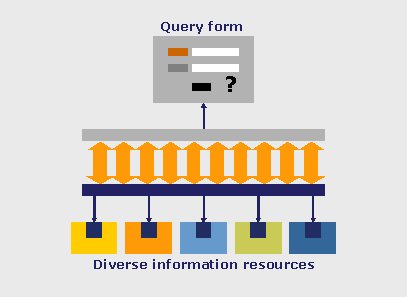
We can describe metasearching as just-in-time processing. That is, instead of pre-processing the data, the metasearch system processes it only when the user launches a query. Metasearch systems, therefore, hold information about how a resource can be searched and how results can be extracted from it, but they do not contain any of the data that is stored in any of the resources that they can access. For an in-depth discussion of metasearching, see Sadeh [2].
In federated searching, a wealth of information is incorporated into a single repository that can be searched (Fig. 2). In this model, the information is processed prior to the user's search. From the end-user's point of view, federated searching and metasearching may seem similar, because both provide a single interface to multiple resources, but they actually differ in many respects. The pre-processing taking place in a federated searching environment, which we can describe as just-in-case processing, offers new opportunities regarding search methodologies and the presentation of results. For example, a ranking algorithm can be applied to each data element stored in the repository, unrelated to any future user query. Such an algorithm can take into account the number of times that an article has been cited, the number of articles that the author has published, the number of times that a book has been borrowed, a journal's impact factor, and other parameters. A federated searching system can use the calculated rank to better evaluate the relevance of the specific item once it has been retrieved as the result of a query.
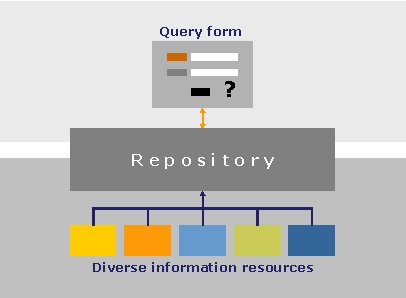
Looking back a few years, we can see that the need for a single search interface to multiple resources arose some time ago, and, in fact, metasearching and federated searching have been available for quite some time. Such systems originated in a variety of environments; for example, Elsevier, a publisher offering numerous journals, created a federated search mechanism enabling its users to search all its e-journals through its ScienceDirect service. As Elsevier acquired other publishers, it was able to add their journals to the same platform.
Database vendors developed similar mechanisms. For example, Ovid provides a single interface to a few hundred databases that it publishes, and still retains them as separate databases. Commercial organizations were not the only ones that addressed the need for a single search interface; several large research institutions created a local environment based on federation. For example, the Los Alamos National Laboratory and the OhioLink consortium in the United States, the University of Toronto in Canada, the Technical Knowledge Center of Denmark (DTV), and the Max Planck Society in Germany all offer large, diverse collections of e-journals that they store locally. These institutions have implemented federated searching to provide a single search interface across their electronic collections. However, not all organizations have the resources to adopt this just-in-case approach. Furthermore, with the rapid increase in the number of heterogeneous resources that institutions offer their users, a single federated searching system can serve only as a partial solution.
Library system vendors took a major step toward metasearching when they implemented the Z39.50 search-and-retrieve protocol, which enables them to provide access to library catalogues. Despite the wide adoption of this protocol, this solution could not scale up to provide a single access point to numerous resources. Hence, we saw the emergence of dedicated metasearch systems as we know them today.
The market's quick acceptance of metasearch systems indicates that libraries do indeed have a need that these systems can fulfil. For example, well over 500 institutions have acquired the Ex Libris MetaLib system since 2001, and many other such metasearch systems are offered in the marketplace. The ability to provide a single, friendly interface to multiple resources (Fig. 3) enables libraries to better address the changing expectations of their users, users who in the meantime have become accustomed to Google and Amazon.
Libraries have not only adopted metasearch systems at a rapid pace, but they have also advocated the development of new standards related to the metasearch process and are sharing their concerns with information providers and metasearch system vendors about the accuracy of searches and the burden that remote searches place on target resources. The active involvement of information providers kicked off the NISO Metasearch Initiative [3], whose aim is to provide the industry with a set of standards that will facilitate and optimize metasearching. This NISO initiative has been the focus of much discussion in the last couple of years, and apparently numerous stakeholders - publishers, librarians, and metasearch system vendors - agree on the value of formulating standards in this area.
Of particular interest to the providers of metasearch systems are the Semantic Web developments spearheaded by Tim Berners-Lee and the World Wide Web Consortium (W3C). A Semantic Web approach would facilitate the interaction between a metasearch system and any number of target resources without requiring prior programming for each target resource. The ideal solution is for the metasearch system to receive resource-specific information at the time of the actual interaction and formulate the flow of the interaction on the basis of this information. For a discussion of the relevance of the Semantic Web to metasearching, see Sadeh and Walker [4].
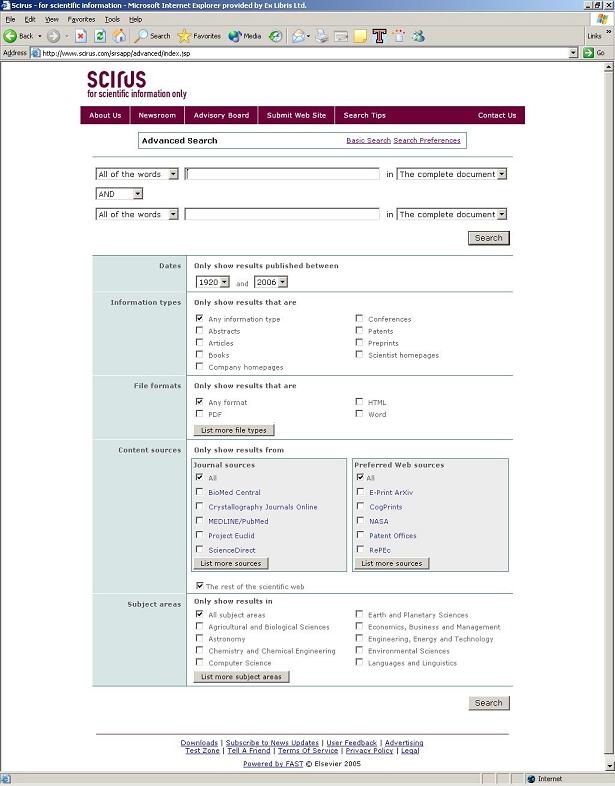
Scirus [5] is the first system that comes to mind when the question of federated searching over heterogeneous data resources arises. Developed by Elsevier and powered by Fast Search & Transfer (FASTTM) technology [6], Scirus contains information from multiple resources, such as BioMed Central, Crystallography Journals Online, MEDLINE, ScienceDirect, arXiv.org, CogPrints, NASA technical report servers, and other publishers. It also includes 200 million science-related Web pages that have been harvested from the entire Web, including access-controlled sites. Both simple searching and advanced searching are available (Fig. 4). The latter enables you to limit your search to specific types of material (for example, articles, books, company home pages, or conferences), file formats, content providers, or subject areas (selected from a list of more than twenty).
When Scirus was first launched, some librarians were concerned, since much of the information harvested from the Web was inaccurate and irrelevant; however, as the system continued developing, it became more refined, and it is now delivering more accurate results. According to the Scirus Web site, the system "has proved so successful at locating science-specific results on the Web that the Search Engine Watch Awards voted Scirus 'Best Specialty Search Engine' in 2001 and 2002" and the Web Marketing Association granted it the Best Directory or Search Engine Website WebAward in 2004 [7]. Nevertheless, because Elsevier has limited itself to a specific set of resources for the creation of Scirus, the system does not cover the whole spectrum of scholarly data.
Google Scholar has its roots in a joint project with CrossRef, an independent association founded and directed by publishers [8]. In 2001, CrossRef launched an initiative aimed at creating a cross-provider repository available for searching. Within a year, the CrossRef CrossSearch project had reached the first beta phase, with six major publishers in partnership with FAST [6], who provided the searching technology used. As a result of internal debate at CrossRef and the involvement of Google in the project, a second beta phase pilot was launched in 2004 - this time in cooperation with Google. According to the CrossRef Web site, "through a special, reciprocal arrangement between Google and CrossRef, this Pilot launches a typical Google search but filters the result set to the scholarly research content from participating publishers, with the intent of reducing the noise produced by general web searches" [9].
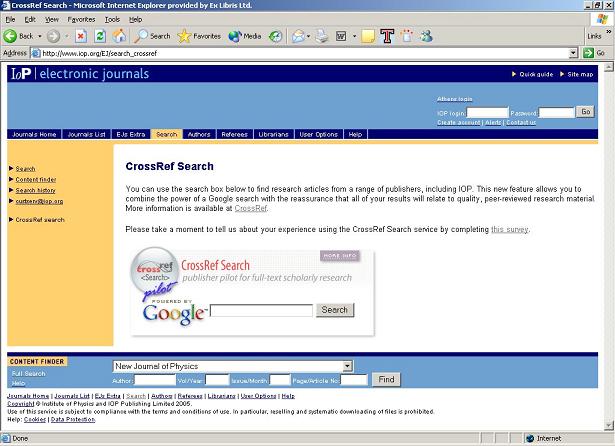
The resulting cross-resource, full-text index is currently available as part of the CrossRef CrossSearch pilot project, which is running through 2005 and whose stated purpose is "to determine the value to the scholarly community of a free, federated, full-text, interdisciplinary, inter-publisher search focussed on the peer-reviewed scholarly literature" [9]. Currently, the pilot covers approximately 6.5 million items from the content of 45 of the 1488 participating publishers and societies. Partnering publishers, such as Nature Publishing Group and the Institute of Physics, provide access to CrossRef CrossSearch from their Web sites [10] [11] (Fig. 5).
The launch of Google Scholar in November 2004 clearly surprised many in the information science community, including CrossRef members. Google Scholar is an ambitious project that is to be applauded, aiming higher than any of the other large federated searching systems. But a year after the service's initial beta release, the jury is still out. Regardless, it has generated much interest and discussion in information science forums.
Google Scholar is easy to use. It has a familiar look and feel, and it is accessible from anywhere, including Internet cafés all over the globe. It is extremely fast, it covers a broad, heterogeneous range of information sources, and it does not require any specific query structure. Now let us look at some other aspects of Google Scholar that might shed light on its usefulness as a scholarly resource.
The major questions about Google Scholar relate to the scope, coverage, and accuracy of the content. Google Scholar does not disclose information about its content. At the SFX-MetaLib User Group (SMUG) meeting that took place in June 2005 at the University of Maryland, Anurag Acharya, the chief engineer of Google Scholar, talked about providing the "best possible scholarly search" and a "single place to find scholarly materials" covering "all research areas, all sources, all time" [12]. At the time of the writing of this article, the goal has not been fully achieved.
First, scholarly materials provided by many publishers, for example, Elsevier, the American Chemical Society and Emerald, are not yet included in Google Scholar, although the metadata describing some of these publishers' materials finds its way to Google Scholar via other channels, such as the National Library of Medicine's PubMed.
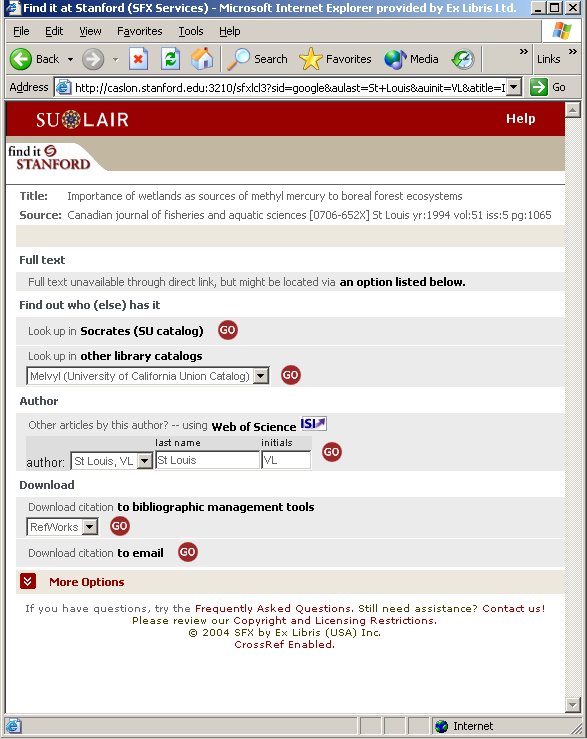
Second, the material that Google Scholar incorporates from a publisher does not always provide complete coverage. Furthermore, updates are not frequent enough to always include the most recent articles.
An enlightening review by Peter Jacso compares the coverage of Google Scholar and that of the original publisher's repository [13]; the results of his comparison indicate that Google Scholar provides only partial coverage. Although the review was published in December 2004, the situation is similar almost a year later. For example, a search in Wiley InterScience for "tsunami" in the title field yields seven results, whereas a search in Google Scholar with the scope limited to Wiley InterScience yields only five results - articles published in 2005 do not appear. A search in Google Scholar for "antimatter", with the scope limited to the Institute of Physics, misses three articles (published in 1973, 1999, and 2003).
When a user knows exactly what he or she is looking for, the partial coverage problem is less serious because the person is aware that the item is missing and can check other databases, such as those that are targeted to the user's area and are more up to date. However, when users are looking for content without knowing which articles, books, or other materials have been published in that area, they might miss valuable information by relying solely on Google Scholar. For some users, such as undergraduates who are looking for any available material, such partial coverage matters less; for researchers, the unrecognized absence of relevant material can be critical.
Another issue worth noting is the definition of scholarly materials. Here, too, we are not sure how Google evaluates what it finds and what criteria it uses for categorizing materials as scholarly or not, except for the obvious cases in which it harvests publishers' sites.
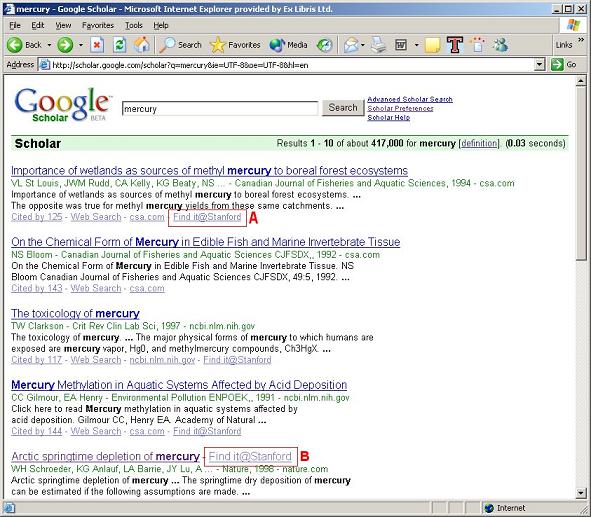
Google Scholar offers a multidisciplinary repository. Unlike metasearch systems that by nature provide both the library and the end-user with tools to define the scope of a search and send a query to only the most relevant resources, Google Scholar, by default, uses its entire repository to provide results. Hence, a search for "mercury", for example, yields results relating to the planet, the chemical element, and the musician Freddie Mercury (though the latter does not appear at the top of the list). This approach clearly facilitates interdisciplinary research but can hamper the effort to focus on a specific discipline.
The problem of the search scope has resonated enough to bring about the introduction of a new feature in the Google Scholar advanced search interface - the option to limit the search to one or more broad subject areas: biology, life sciences, and environmental science; business, administration, finance, and economics; chemistry and materials science; engineering, computer science, and mathematics; medicine, pharmacology, and veterinary science; physics, astronomy, and planetary science; social sciences, arts, and humanities. However, libraries cannot control this list, and the issue of whether the results of a search limited to a specific subject area are, indeed, applicable to that area has yet to be examined. A quick test shows that among the articles that come up in a search for "Mars" in the subject area of social sciences, arts, and humanities is "History of water on Mars: a biological perspective", published by researchers from the Space Science Division, NASA Ames Research Center. We can safely conclude that this article is not related to the selected subject area. It seems that Google Scholar has developed automated procedures to categorize the materials that it harvests, but such procedures still fall short of the database providers' classification methods, which are based on careful, human processes.
One of the major contributions to the success of Google in general is the relevance-ranking feature. Usually people find what they are looking for on the first page of results, thanks to the PageRank algorithm that Google uses to evaluate each Web page prior to user queries and without any relation to them. This algorithm is based on the number of links that point to the page from other Web pages, the number of links that point to those other Web pages, and so on. For Google Scholar, the algorithm had to be changed because of the different nature of the data. According to the information on the Google Scholar Web site, "the relevance ranking takes into account the full text of each article as well as the article's author, the publication in which the article appeared and how often it has been cited in scholarly literature" [14].
Here, however, we run into a few problems. First, because Google has not publicized its content or the manner in which it determines whether material is 'scholarly literature', we have no way of knowing whether the number of citations is complete and accurate. Furthermore, as Google does not always identify duplicates (probably because of the heterogeneous nature of the metadata that it discovers while crawling the Web), the number of citations may not be realistic. For example, when we search in Google Scholar for the article "Library portals: toward the semantic Web", Google Scholar shows that the article has been cited six times; nevertheless, when we click the 'Cited by 6' link and look at the citations carefully, we can see that one publication appears twice, as both the first and sixth citations. Moreover, at least two other known citations are missing altogether. Yet Google Scholar uses citations to determine relevance ranking.
Whether systems that enable searches across scholarly materials should display the results of users' queries by relevance is not a simple question to answer. Relevance, in at least some cases, depends on context. Relevant to whom? For what purpose? Does the same relevance apply to an undergraduate who is looking for material for an introductory course in physics and a scientist who is searching for recent publications related to current research? The student might need a well known article that is not new, but the scientist is almost certainly not looking for that article. Furthermore, the usefulness of an item depends on the discipline of the researcher; for example, the articles that come up in a search for "plague" will differ in their relevance to a scholar of twentieth-century French literature and to an epidemiologist.
Roy Tennant offers a noteworthy example in his presentation "Is MetaSearch Dead?" [15]. He searched for "tsunami" in Google Scholar, Google, and the National Science Digital Library (NSDL). The first page of results in Google Scholar yielded no items with general information that an undergraduate would find useful. In Google, the first page included three results with useful scientific information, seven relief effort sites, and at least seven sponsored links (advertisements). But the first page of results at the NSDL listed 20 sites with useful scientific information. Perhaps these sites are hiding somewhere in the Google Scholar result list, but it is doubtful that any user will be able find them among the tens of thousands of results.
Interestingly, most bibliographic databases do not return results by relevance; such databases typically list results by date in descending order and enable the user to re-sort them by other criteria, such as author and title. Metasearch systems retrieve the results from the databases in the order set by each database and sometimes also provide options for other modes of display. For example, MetaLib from Ex Libris displays the results in the original order dictated by the database and also as one merged, de-duplicated list sorted by relevance. The end-user can re-sort the merged list by author, title, and date.
Google Scholar's choice of sorting criteria used for the display of scholarly materials represents a significant potential for power. People who are used to finding what they are looking for on the first page in Google are likely to adopt the same behaviour when using Google Scholar; thus highly cited items will gain more citations and will continue to appear at the top of the page. It is not obvious that this method of displaying results, the only one that Google Scholar provides, is indeed appropriate for scientific research.
One of the greatest advantages of Google Scholar, inherited from Google, is the simple interface, in terms of both design and functionality. Extremely intuitive, it is also available from any computer, with any browser. On the one hand, this interface is convenient for end-users, but, on the other, it does not allow for integration within a virtual library environment. Libraries typically want to provide their patrons with a complete user experience, encompassing content, design, and services, and they manage to do that quite successfully with their metasearch systems. With these systems, not only can libraries customize the user interface to create their own look and feel (typically for institutional branding), but they can also integrate their metasearch systems with their authentication environment, course management systems, and institutional portals; they have control over the resources that they offer, the categorization of those resources, the terminology, the display options, and the services that they provide for the end-users. Such services include a link to the library's holdings - be they electronic or print, local or remote; links to other relevant resources; functions that enable users to download records in the appropriate format, save and send citations, define alerts, create lists of favourite resources, and more.
Google Scholar, however, does not support integration in the virtual library environment. The Georgia State University library site, for example, makes an effort to introduce Google Scholar to its patrons [16], but when a patron clicks the link to Google Scholar, a new window opens without any university branding - the same Google Scholar page that users at any other library see.
Of much concern at the time that Google Scholar was launched was the lack of library control over the link to the electronic copy that Google Scholar provided for citations. Google Scholar did not address the 'appropriate copy' problem, despite the generally accepted solution offered by the OpenURL framework. As Herbert Van de Sompel, inventor of the OpenURL framework, explains, "This problem refers to the fact that such linking frameworks fail to provide links that lead from a citation of a journal article to the appropriate full-text copy of that article. A full-text link typically leads to a publisher-defined default copy of the article, which usually resides in the publisher's repository. However, access to the copy of the article that is appropriate in the context of a certain user may very well require the provision of an alternative link" [17].
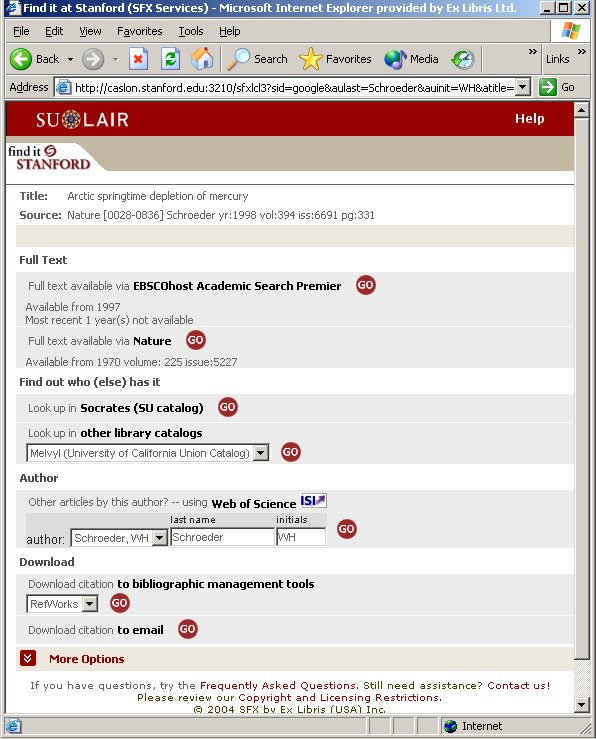
As a result of these concerns, Google Scholar was quick to adopt the OpenURL standard. Following a short pilot project with selected libraries, Google Scholar became officially OpenURL enabled in May 2005. If a library opts to take advantage of this compliance, Google Scholar provides library-defined links to the user's institutional link server, for example, SFX, for many of the displayed citations (as long as specific metadata elements, such as ISSN and DOI, are available). On the basis of the user's IP or the affiliation preferences that he or she has set, Google Scholar identifies the user as belonging to a specific institution [18]. The provision of a link to the institutional link server puts the control back in the hands of the librarians and allows the users of Google Scholar to take advantage of library holdings and services.
Under the assumption that users are typically most interested in electronic full text, Google Scholar has been designed to display a link to the institutional link server in a prominent place - next to the title - when the electronic full text is available, and when it is not, the link is displayed with the other links, underneath the citation (figs. 6-8). For Google Scholar to be able to alter the display of the link according to the availability of the full text, libraries must provide Google Scholar with the details of their electronic holdings. SFX, the link server from Ex Libris, automates the provision of holdings information to Google Scholar so that this task does not become a burden on the library staff.
Many librarians, however, did not readily accept this requirement. First, it contradicts one of the fundamental concepts of the OpenURL framework: the library should have full control over the user experience regarding the delivery of services. Second, because Google is a commercial company, some librarians are concerned that providing Google Scholar with holdings information may serve Google for matters other than the provision of links and hence does not comply with their mission as educational or research institutions that are commercially neutral. And third, this move requires that libraries maintain the information in a form that Google Scholar can harvest. In his presentation at the SMUG meeting, Acharya offered compelling arguments for providing holdings data. He highlighted the benefits of having the links in Google Scholar and explained the Google Scholar philosophy of informing the user in advance of whether the desired service, in this case the link to the full text, is available. Assuring libraries that they have a partner they can talk to, he emphasized the need to "step out of the mutual comfort zones" and work together.
Finally we come to a question that continues to puzzle the library community: what is the business model that Google has adopted for Google Scholar? At the time of the writing of this article, the Google Scholar site was not displaying advertisements. However, Google Scholar was still in the beta phase. If this policy changes, libraries may reconsider providing their holdings to Google Scholar and promoting its use in their institution. As with many other questions concerning Google Scholar, we can only wait and see what happens.
The library community is divided between those who welcome Google Scholar and those who reject it. A recent study conducted at the University of California (UC) reveals the varying attitudes of librarians toward Google Scholar [19]. Some believe that it is a great tool and promote it actively, whereas others do not use or recommend it and prefer their institutional databases, which they describe as "reliable" or "real". In many cases librarians use Google Scholar as an additional resource when they are looking for old materials, Web materials not found in the institution's databases, or materials that relate primarily to interdisciplinary topics. According to some, the fact that Google Scholar provides links to the UC SFX link server (UC-eLinks) makes it even more valuable. A number of librarians also recommend Google Scholar to non-affiliated users, who have no access to the institutional databases. Librarians who find Google Scholar useful are trying to figure out ways to instruct patrons about when it is appropriate to search in Google Scholar as opposed to the institution's databases.
Google Scholar is clearly gaining patrons' attention at university libraries, and librarians are responding accordingly. At UC some librarians include Google Scholar in the curriculum of classes that they teach or provide explanations to patrons at the reference desk. The Los Angeles campus (UCLA) Web site offers instruction on Google Scholar, search engines, databases, and the research process [20]. By comparing searching in Google Scholar to searching in PsycINFO, the site enables users to figure out what they win and what they lose with each of these resources. In addition, the UCLA Web site provides a comprehensive explanation about using the school's SFX link server from Google Scholar [21].
Other institutions post pages with frequently asked questions about Google Scholar, such as the page on the Web site of the University of Nevada, Las Vegas [22], which states, among other things, that "While we encourage you to try Google Scholar, keep in mind that this software is 'in Beta.' Beta status indicates that Google Scholar is still in development, and you may therefore encounter some inconsistencies or peculiarities. You may wish to supplement your research by searching some of the many other databases found on the 'Find Articles and More' page".
Google Scholar may provide an easy way to search. However, with the constantly increasing quantity of scholarly data, Google Scholar will soon be facing a new challenge, as will database providers and metasearch systems: the comprehensive presentation of search results to the user.
The assumption underlying the implementation of relevance ranking and its use as a sorting order is that end-users will not scroll down and scan large amounts of data. Therefore, the results that are most likely to suit their research needs should appear at the top of the list. However, this sorting order has several drawbacks. As mentioned earlier, users have different research needs, and an item that is most relevant to one user may be less relevant to another.
Another problem with presenting search results in any type of linear list is that sometimes there are a great many results. Some users, particularly those who are novices, may not know how to define their queries effectively; however, once the system analyzes the set of results and provides options to narrow down the list, such users can easily drill down to the relevant subset of results.
Several companies have developed technologies that enable sites to cluster search results and offer drill-down options to end-users. One such company is Vivísimo [23], whose technology can be seen on the Web site of the Institute of Physics (IOP) [24]. Let us look at an example of how the Vivísimo technology works.
I am looking for information about the sine-Gordon equation. When I search the IOP Web site, the traditional display provides a list of 95 articles. However, I can opt to see the list clustered (Fig. 9). As explained on the IOP site, "when you cluster your search results, you will find them presented (unchanged) on screen alongside folders representing the clusters generated. The folders are sorted according to the number of search results in each, and according to the overall rank of the individual search results in the search engine's output" [25]. I can select any of these topic clusters, thus narrowing down my list of results, and I can drill down even further and see only the results for a particular subtopic. In our example, I quickly identify "soliton" as the topic of interest, thus decreasing the number of relevant results to 35; and if I am seeking information about magnetic fields, I can drill down further to the "magnetic fields" subtopic and see a list of four records. Note, however, that the Vivísimo IOP implementation clusters only the first 250 records.
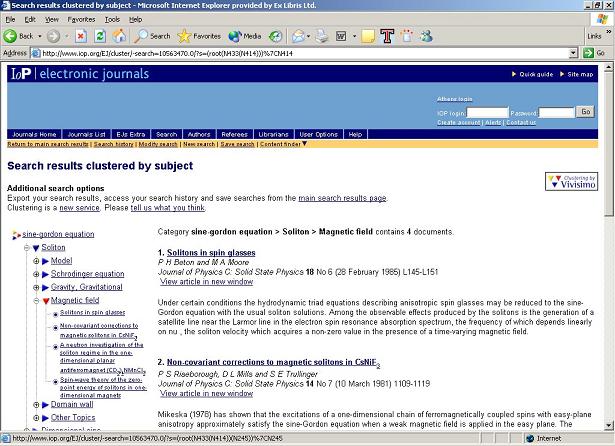
Another example is the Vivísimo demonstration implemented over the PubMed database[26]. This demonstration clusters only 100 records but enables the user to choose a clustering scheme for the results (Fig. 10): a combination of title, abstract, and medical subject heading (TiAbMh); title and abstract (TiAb); medical subject heading (Mh); author (Au); affiliation (Ad); or date of publication (Dp). With each of these schemes, the user can drill down and narrow the result set as necessary.
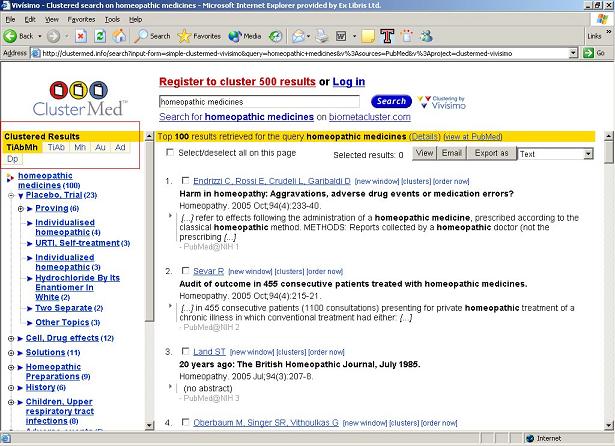
The Vivísimo model in these examples is based on just-in-time processing. Because it does not hold the initial data set, Vivísimo can access and manipulate the records only after the user sends a query and the original database (IOP or PubMed, in the examples cited earlier) returns the results. Because the delivery of the data is time-consuming, the processing of the records applies to the first results only. In other words, the processing is applied to a subset of the actual results.
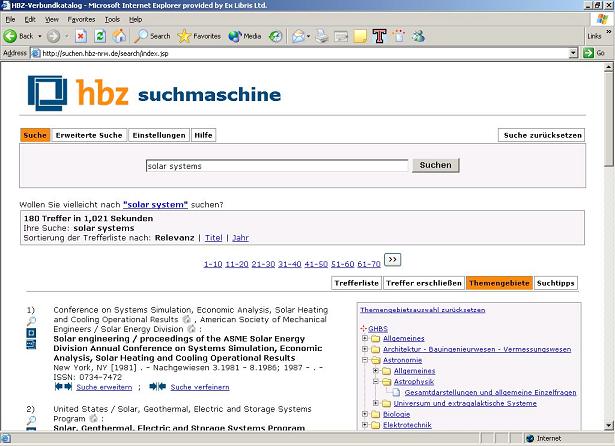
Keeping in mind the distinction made earlier between just-in-time processing and just-in-case processing, let us examine similar systems that analyze the records prior to the user's search. One example is Scirus [5], which relies on the technology provided by FAST [6]. Another example is Hochschulbibliothekszentrum des Landes Nordrhein-Westfalen (HBZ), an implementation of FAST technology to provide sophisticated searching and clustering over a very large union catalogue based on the Ex Libris ALEPH 500 library system [27]. As we can learn by launching a search on the HBZ site, the performance is much better than what we saw in the Vivísimo example; processed and analyzed in advance, all the data on HBZ is immediately available to the search engine. Besides the sophisticated searching options and the initial result list sorted by relevance (which the end-user can re-sort), the HBZ system provides various ways of drilling down and focusing on a specific subject area, author, type of material, and more, all derived from the current set of results (Fig. 11).
Google Scholar is becoming the object of greater attention from libraries, patrons, and publishers, regardless of librarian approval. Depending on Google's plans, Google Scholar may turn into a core resource for researchers. Perhaps the library community should encourage patrons to use this search engine when appropriate and keep a watchful eye on the quality of the results.
Google's attentiveness to the library community, as evidenced by the rapid implementation of the OpenURL standard in Google Scholar, indicates that this service might well be evolving in the right direction. Nevertheless, it is not likely to replace metasearch systems in the short term. A locally controlled and branded system that enables librarians to offer accurate, up-to-date, subject-specific research data and to customize relevant services renders metasearch systems highly valuable to the scholarly community.
[1] About Google Scholar
URL: <http://scholar.google.com/scholar/about.html> (October
16, 2005)
[2] Tamar Sadeh. "The Challenge of Metasearching." New Library World, vol. 105, no. 1198/1199 (2004): 104-112.
[3] NISO Metasearch Initiative, Main Page
URL: http://www.lib.ncsu.edu/niso-mi/index.php/Main_Page> (October
20, 2005)
[4] Tamar Sadeh T. and Jenny Walker. "Library portals: toward the semantic Web." New Library World, vol. 104, no. 1/2 (2003): p. 11-19.
[5] Scirus
URL: <http://www.scirus.com/srsapp/> (October 22, 2005)
[6] FAST, company Web site
URL: <http://www.fast.no> (October 22, 2005)
[7] About Scirus
URL: <http://www.scirus.com/srsapp/aboutus/> (October 22, 2005)
[8] CrossRef, Homepage
URL: <http://www.crossref.org/> (October 10, 2005)
[9] CrossRef CrossSearch
URL: <http://www.crossref.org/crossrefsearch.html> (October 10,
2005)
[10] CrossRef CrossSearch access from Nature
URL: <http://www.nature.com/search/search_crossref.html>
(October 22, 2005)
[11] CrossRef CrossSearch access from IOP
URL: <http://www.iop.org/EJ/search_crossref> (October 22, 2005)
[12] "Google Scholar & Libraries." Presentation by Anurag Acharya at SMUG meeting, University of Maryland, June 9, 2005.
[13] Peter Jacso. "Google Scholar Beta." Péter's Digital Reference Shelf, December 2004
URL: http://www.gale.com/servlet/HTMLFileServlet?imprint=9999®ion=7&fileName=/reference/archive/200412/googlescholar.html> (October 22, 2005)
[14] Google Press Center: Product Descriptions
URL: <http://www.google.com/press/descriptions.html> (October22, 2005)
[15] "Is MetaSearch Dead?" Presentation by Roy Tennant of the California Digital Library, March 2005.
URL: <http://escholarship.cdlib.org/rtennant/presentations/2005niso/> (October 19, 2005)
[16] Georgia State University Library
URL: <http://www.library.gsu.edu/googlescholar/>
[17] Herbert Van de Sompel and Oren Beit-Arie. "Open Linking in the Scholarly Information Environment
Using the OpenURL Framework." D-Lib Magazine, vol. 7, no. 3 (2001).
URL: <http://www.dlib.org/dlib/march01/vandesompel/03vandesompel.html> (October 22, 2005)
[18] Google Scholar, preferences page
URL: <http://scholar.google.com/scholar_preferences> (October
22, 2005)
[19] E. Meltzer. "UC Libraries Use of Google Scholar." Aug. 15, 2005.
URL: <http://www.cdlib.org/inside/assess/evaluation_activities/docs/2005/googleScholar_summary_0805.pdf> (October 10, 2005)
[20] UCLA Libraries: Search and Find: Google Scholar, Search Engines, Databases, and the Research
Process.
URL: <http://www2.library.ucla.edu/googlescholar/searchengines.cfm> (October 19, 2005)
[21] UCLA Libraries: Search and Find: I have done my search. Now how do I get the material?
URL: <http://www2.library.ucla.edu/googlescholar/3174.cfm> (October
16, 2005)
[22] UNVA Libraries: Google Scholar FAQ
URL: <http://www.library.unlv.edu/help/googlescholar.html> (October
21, 2005)
[23] Vivísimo, company Web site
URL: <http://vivisimo.com/> (October 16, 2005)
[24] Search IOP Electronic Journals
URL: <http://www.iop.org/EJ/search> (October 22, 2005)
[25] IOP Help: What is a cluster?
URL: <http://www.iop.org/EJ/help/-topic=cluster/search>
(October 22, 2005)
[26] ClusterMedTM
URL: <http://clustermed.info/>(October 22, 2005)
[27] HBZ suchmaschine
URL: <http://www.hbz-nrw.de/> (October 22,
2005)
Tamar Sadeh brings a computing background to the field of information services for libraries. With a
degree in computer science and mathematics, she spent a number of years developing search engines for structured and
unstructured data. At Ex Libris, a multinational company that develops high-performance applications for libraries and
information centres, Tamar has taken an active role in the definition and marketing of the MetaLib®, SFX®, and Verde
technologies. Tamar is the author of several papers on various subjects related to information sciences.
|