 High Energy Physics Libraries
Webzine
High Energy Physics Libraries
Webzine| High Energy Physics Libraries
Webzine |
|
HEP Libraries Webzine
Issue 12 / March 2006
24/02/2006
CERN's open access e-print repository, CERN Document Server (CDS), contains open access full-text copies of nearly three quarters of its own recently-authored documents. As a result of retrospective scanning projects, just over half of all documents written since CERN's creation in 1954 are available. Metadata harvesting from a variety of external sources contributes to the identification of CERN-authored documents such that close to 100% are believed to be found. Full-text files are obtained through author submission, retro-scanning and upload from external sources. A growth in the numbers of metadata records and full-text files is demonstrated between 2005 and 2006 and the improvements can be linked to certain projects carried out by the Library staff. Ongoing and future projects to capture missing files include scanning projects, attempts to raise author awareness, and direct author contact.
Institutional repository, open access, harvesting, author submission, statistics,
data, coverage, e-prints
CERN Document Server (CDS) is a database used by many different departments at CERN to take advantage of the file storage and search facilities or to make their files more widely available. It combines the traditional Library holdings of books and journals (increasingly in e-format) with the institutional repository of preprints and published articles and also welcomes collections of other types from departments such as the CERN Photographic Service, the Finance Office, and the Press Office. The Library staff have succeeded in turning the database into the primary literature resource for the physics community at CERN by harvesting and uploading metadata and full-text files for relevant items, not just written by CERN staff, but from other laboratories and obtained from other sources such as arXiv.org (further details in [1] and [2]). Metadata harvesting is performed at such a level that the Library believes it retrieves bibliographic records for almost 100% of CERN's own documents.
For many reasons it has been useful to extract certain parts of the collection which have a CERN focus and offer them separately to users. For this reason you will see on the CDS home page (figure 1) an area on the right hand side called 'focus on' which pulls together certain collections of items pertinent to different departments or users at CERN and begins with all 'CERN articles and preprints'
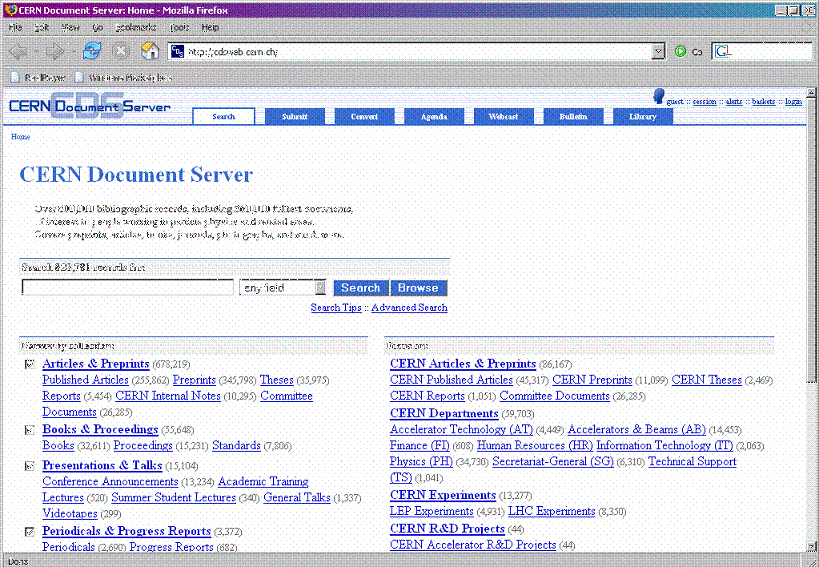
Before discussing collection statistics it is useful to first briefly make clear the history of the CERN preprint collection and explain the practicalities of the mandate to deposit.
The physics community has a long history of distributing preprints for quick communication of results and CERN began collecting copies of its own preprints, and those sent from other laboratories, from the start of its existence in 1954.
The Library's responsibility to track the laboratory's own preprints was explicit in the CERN rules which required all authors to send a copy of their preprint to the Library where they were (and still are) stored in filing cabinets ordered by report number. The rules were revised in 2001 and now request submission in electronic form:
"A document which satisfies the conditions for being a CERN Scientific Document, should be submitted to the SIS [Scientific Information Service which includes the Library] in complete electronic form. The full bibliographic information (including abstract) and the location(s) of the full text of the document have to be supplied." [3]
Although the Web was created at CERN, among the first to exploit its potential was Paul Ginsparg in the USA who created the hep-th preprint server in 1991 and in 1993 gave it a Web interface at xxx.lanl.gov (now arXiv.org) [4] and it was using his model that CERN also created an electronic preprint repository in 1993. The arXiv repository is primarily a quick communication channel for physicists and as such does not harvest from other institutional repositories. Because of its now famous reputation, many CERN authors submit to arXiv and not to CDS. It is not always possible to automatically identify CERN-authored documents in arXiv but because CERN prefers to enlarge its repository with papers from related fields, by default, CERN papers are uploaded among the many others from these fields of interest and are manually identified at a later date. In effect, this means that CDS contains more papers than arXiv in certain fields of relevance to CERN.
This practice of deposit in other repositories such as arXiv is not discouraged by CERN, but instead records and full-text are harvested from these external sources and uploaded to the CERN repository. Although the rule to submit to CDS exists, in general CERN does not strictly enforce it using coercion but rather using encouragement and reminders. Library staff time is better spent on finding papers that are not available anywhere than on telling those authors who do submit that they are doing it in the 'wrong' way.
Official CERN divisional/departmental reports are always submitted via departmental administrative channels direct to CDS. The rest are requested, though not always supplied, from CERN authors and it is the responsibility of the Library to locate and upload missing papers.
Standards for defining and measuring repository content do not yet exist because repositories are commonly not yet large enough for such studies to be useful. Presumably the time will soon arrive when more institutions start to measure their repository's growth.
If a measure of the success of a repository is in calculating how near to 100% of an institution's publications the repository contains, then evidence is scarce. arXiv.org publishes a monthly record of submissions at http://arxiv.org/show_monthly_submissions but as the repository is not belonging to one institution, it is impossible to know what 'success' this represents. Paula Callan from Queensland University of Technology (QUT) has in the last couple of years begun to promote the success of QUT's new repository although this has so far tended to focus on the rate of submission rather than the growth of content [5] as in the early days this is a much more encouraging indicator.
CERN's repository contains details of nearly 70,000 articles and preprints from CERN authors alone. Therefore, an analysis of its success in garnering its own documents is becoming useful for Library staff to identify the areas where future efforts should be targeted.
Through the use of MARC tags, CERN-authored documents are identified as such with a tag in field 690C and also receive a second tag in 710 to identify the department at CERN from which the author(s) originates. These tags are used to build the 'focus on' collections previously mentioned.
Publication references are added in field 773 when known, either as reported by the author/submitter or by locating the matching reference from a publications database. From this field, derived URLs are created to link directly when possible to the published article using the GoDirect system created at CERN [6]. The full-text file of the preprint, however, is a stored URL in the 8564 field and is therefore easily separated from the publication link. If permission is granted by a publisher to download a copy of a paper to CDS and make it freely available, then the published version is linked not only by the derived URL but also receives a direct link to the full-text file using the 8564 field; therefore any link in this field is to an open access copy of the item.
Using a combination of such tags it is possible to calculate how many records in CDS are for CERN documents and how many have full-text, open access files attached. These files might be uploaded to CDS by the author or on the authors' behalf, or are links from CDS to the freely available copy at a reliable source elsewhere, for example arXiv.org.
No systematic collection of statistics has been made in the past, so unfortunately we have only the figures collected approximately a year ago with which to compare those generated this year.
Regarding dates, there is no indicator in the bibliographic record of precisely when the electronic, OA, full-text copy of any item was obtained; the dates recorded in the submission relate to the date the document was "written" as defined by the submitter, and the publication date if known.
Although tags are used to identify the source of the files, these have not been analysed at this time.
The number of articles written each year has generally increased along with the increase in CERN staff, and the numbers of experiments. The drop in recent years can be partially explained by the closure of the LEP machine and subsequent drop in the volume of physics results published. The experiences of Library staff and discussions with authors suggest a second reason for this drop in the numbers of identified papers: authors do not always upload their documents before publication and for the same reason they are not yet found in external sources. This explains why figures for the most recent years are temporarily low.
Although daily searches are performed on many external bibliographic sources, for several reasons it may be some time before records are found: long time lag to publication, delay in indexing, or missing author affiliation. This retrieval of metadata for items not immediately uploaded by the author temporarily affects the percentage of coverage in the most recent years causing it to fluctuate (figure 3). Since the 2005 data were collected, the percentage of OA files available for 2004 has dropped significantly from 89% to 68%. However, this is deceptive and does not correspond to a decrease in the number of files available, which have actually increased from 1200 to 1500, but rather to a higher increase in the number of metadata records, which have almost doubled. In other words, harvesting activity since 2005 has found more metadata than full-text files for the year 2004 and therefore the proportion of full-text files to metadata has fallen.
In 2005 data only partial data was recorded and so it exists only for 1960, 1970, and 1980, and from 1990 onwards.
Verbal evidence from authors suggests that they prefer not to upload all conference papers because doing so would show how often they re-used the same material, and also therefore be a waste of time. For this reason, some data excluding conference papers were collected. Although a difference was shown when conference papers were removed, with percentages improved across all years, the difference was not as large as might have been expected.
From 1998 the increase in actual numbers of metadata records obtained between 2005 and 2006 can be clearly seen in a direct comparison of the numbers (figure 4). In contrast, pre-1998 the number of records drops between 2005 and 2006. One reason for this reduction could be the de-duplication of metadata records, concentrating in the 90s, performed by Library staff. But as we have begun to study the collections in more detail, we have learned more about them and about errors we might have made and so the drop could also be attributed to the inclusion of some records which in 2006 were not included due to better metadata tagging or to better search formulae.
Other interesting features of the graphs are noted on figure 5. The huge leap in full-text coverage starting from the low point in 1991 corresponds to the creation of the electronic repository in 1993. This success was reinforced in 1996 when authors became able to submit papers themselves.
As previously mentioned, Library staff perform ongoing work to de-duplicate metadata records. Due to slight variations in the record formats harvested from different sources, it is not always possible to match the metadata fields exactly, leading to some duplication of records. Library staff must check these possible duplicates manually. As some harvested sources contain only metadata and others have full-text files, the activity naturally leads to a reduction in the numbers of records having no full-text file and so an improvement in the percentage of full-text available. Due to the necessity of completing this activity before beginning a new project aimed at gathering full-text files for items written since 1990, the de-duplication efforts have been concentrated on this decade.
The period of much-improved coverage during the 70s and 80s is mainly a result of the ongoing work uploading scanned versions of preprints made at KEK Library in Japan. Although files corresponding to papers written in the 90s could also be added from KEK, the potential is not as great for automatic data processing of scanned versions as opposed to pdf author originals. For this reason, plans are underway to attempt to retrieve these files from authors first before resorting to scanned images.
The recent 5-year (2001-2005) average for OA coverage is 70%. Comparing data for the same 5-year period (2000-2004) from both 2005 and 2006, the percentage drops from 72% to 68% but this conceals a successful increase in numbers of both metadata files and full-text files, the latter having increased for this period from 8000 to 9000 in 2006.
For all years (including pre-electronic archive) the coverage is now 52% which compares extremely well with the coverage in 2005 of 34%. This significant improvement is entirely due to the successful efforts of Library staff to scan and to harvest the full-text files of older material, and to de-duplicate and improve the metadata of CDS records.
Several projects have been completed, are underway, or are planned for finding the full-text for items which have been identified with metadata but for which an OA full-text file is not available in CDS.
Completed:
Ongoing:
Future projects planned:
With these efforts and the continuing publicity campaign amongst its authors, CERN Library hopes one day to reach 100% coverage in the CDS electronic collection.
[1] Nathalie Pignard, Ingrid Geretschläger, Jocelyne Jerdelet: "Automated
treatment of electronic resources in the Scientific Information Service at CERN" High Energy Physics
Libraries Webzine, issue 3, March 2001.
URL: http://library.web.cern.ch/library/Webzine/3/papers/3/
[2] Carmen O'Dell, David Peter Dallman, J Vigen, and Martin Vesely. "50 Years of Experience in Making Grey Literature Available: Matching
the Expectations of the Particle Physics Community". In: 5th International Conference on
Grey
Literature : Grey Matters in the World of Networked Information, GL 2003, Amsterdam, The Netherlands
, 4 - 5 Dec 2003, p. 117-123.
URL: http://doc.cern.ch/archive/electronic/cern/preprints/open/open-2003-053.pdf
[3] European Laboratory for Particle Physics [CERN]. Operational Circular number 6. June 2001.
URL: http://humanresources.web.cern.ch/humanresources/internal/admin_services/opercirc/English/oc-06.pdf
[4] Paul Ginsparg "First steps towards electronic research communication", Computers in Physics: 8(4), July/August 1994, p. 390.
[5] Paula Callan. "Re: Learning from the successful OA IRs". Email posted to AmSci
(American Scientist Open Access Forum) January 20 2006.
URL: http://www.ecs.soton.ac.uk/~harnad/Hypermail/Amsci/5083.html
[6] E. Lodi, M. Vesely, J Vigen. "Link managers for grey literature". In: 4th
International Conference on Grey Literature : New Frontiers in Grey Literature, GL '99, Washington,
DC,
USA , 4 - 5 Oct 1999, p. 116-134. [7] CERN Scientific Information Policy Board. "Continuing CERN action on Open
Access journals and conference proceedings". March 2005.
URL: http://cdsweb.cern.ch/search.py?recid=409692&ln=en
URL: http://library.cern.ch/cern_publications/CERN_exec_board_23.03.05.html
Author Details
Joanne Yeomans
Scientific Information Officer
http://library.cern.ch/
CERN Library
Mailbox C27810
CERN CH 1211 Geneva 23, Switzerland
Email: joanne.yeomans@cern.ch
Joanne Yeomans is currently leader of the User Services section at CERN Scientific Information Service. She is responsible for ensuring the high quality of the service from the Library to the CERN community and in connection with this is active in CERN's Open Access project.

|